
推荐数据的处理是大规模的,在集群环境下一次要处理的数据可能是数GB,所以Mahout针对推荐数据进行了优化。
Preference
在Mahout中,用户的喜好被抽象为一个Preference,包含了userId,itemId和偏好值(user对item的偏好)。Preference是一个接口,它有一个通用的实现是GenericPreference。

因为用户的喜好数据是大规模的,我们通常会选择把它放入集合或者数组。同时,由于Java的对象的内存消耗机制,在大数据量下使用Collection<Preference>和Preference[]是非常低效的。为什么呢?
在Java中,一个对象占用的字节数 = 基本的8字节 + 基本数据类型所占的字节 + 对象引用所占的字节
(1) 先说这基本的8字节
在JVM中,每个对象(数组除外)都有一个头,这个头有两个字,第一个字存储对象的一些标志位信息,如:锁标志位、经历了几次gc等信息;第二个字节是一个引用,指向这个类的信息。JVM为这两个字留了8个字节的空间。
这样一来的话,new Object()就占用了8个字节,那怕它是个空对象
(2) 基本类型所占用的字节数
byte/boolean 1bytes
char/short 2bytes
int/float 4byte
double/long 8bytes
(3) 对象引用所占用的字节数
reference 4bytes
注:实际中,有数据成员的话,要把数据成员按基本类型和对象引用分开统计。基本类型按(2)进行累加,然后对齐到8个倍数;对象引用按每个4字节进行累加,然后对齐到8的倍数。
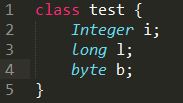
占 8(基本) + 16(数据成员——基本类型:8 + 1,对齐到8) + 8(数据成员——对象引用Integer,4,对齐到8) = 32字节
如此一来的话,一个GenericPreference的对象就需要占用28个字节,userId(8bytes) + itemId(8bytes) + preference(4bytes) + 基本的8bytes = 28。如果我们使用了Collection<Preference>和Preference[],就会浪费很多这基本的8字节。设想如果我们 的数据量是上GB或是上TB,这样的开销是很难承受的。
为此Mahout封装了一个PreferenceArray,用于表示喜好数据的集合
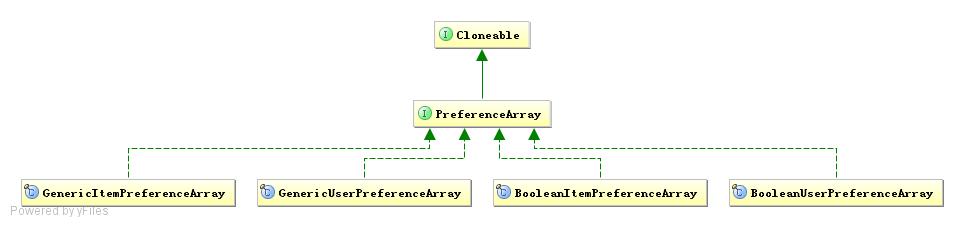

我们看到,GenericUserPreferenceArray包含了一个userId,一个itemId的数组 long[],一个用户的喜好评分数据float[]。而不是一个Preference对象的集合。下面我们做个比较,分别创建一个 PreferenceArray和Preference数组
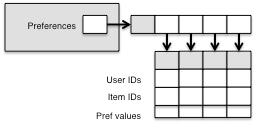
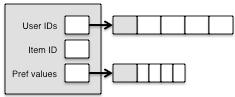
在size为5,但只包含一条喜好数据的情况下:PreferenceArray需要20Bytes(userId 8bytes + preference 4bytes + itemId8bytes),而Preference[]需要48字节(基本8bytes + 一个Preference对象28bytes + 4个空的引用4×3 12Bytes)。如果在有多条喜好数据的情况下,PreferenceArray中将只有一个itemId,这样它所占用的8Bytes微乎其微。所以 PreferenceArray用它特殊的实现节省了4倍内存。
用《Mahout in action》一书中的原话“mahout has alreadly reinvented an 'array of Javaobjects'”——"mahout已经重新改造了Java对象数组"。PreferenceArray和它的具体实现减少的内存开销远远比它 的的复杂性有价值,它减少了近75%的内存开销(相对于Java的集合和对象数组)
除了PreferenceArray,Mahout中还大量使用了像Map和Set这些非常典型的数据结构,但是 Mahout没有直接使用像HashMap和TreeSet这些常用的Java集合实现,取而代之的是专门为Mahout推荐的需要实现了两个 API,FastByIDMap和FastIDSet,之所以专门封装了这两个数据结构,主要目的是为了减少内存的开销,提升性能。它们之间主要有以下区 别:
· 和HashMap一样,FastByIDMap也是基于hash的。不过FastByIDMap使用的是线性探测来解决hash冲突,而不是分割链;
· FastByIDMap的key和值都是long类型,而不是Object,这是基于节省内存开销和改善性能所作的改良;
· FastByIDMap类似于一个缓存区,它有一个“maximumsize”的概念,当我们添加一个新元素的时候,如果超过了这个size,那些使用不频繁的元素就会被移除。
FastByIDMap和FastIDSet在存储方面的改进非常显著。FastIDSet的每个元素平均占14字节,而HashSet而需要84字节;FastByIDMap的每个entry占28字节,而HashMap则需要84字节。
DataModel
Mahout推荐引擎实际接受的输入是DataModel,它是对用户喜好数据的压缩表示。DataModel的具体实 现支持从任意类型的数据源抽取用户喜好信息,可以很容易的返回输入的喜好数据中关联到一个物品的用户ID列表和count计数,以及输入数据中所有用户和 物品的数量。具体实现包括内存版的GenericDataModel,支持文件读取的FileDataModel和支持数据库读取的 JDBCDataModel。

GenericDataModel是DataModel的内存版实现。适用于在内存中构造推荐数据,它仅只是作为推荐引 擎的输入接受用户的喜好数据,保存着一个按照用户ID和物品ID进行散列的PreferenceArray,而PreferenceArray中对应保存 着这个用户ID或者物品ID的所有用户喜好数据。
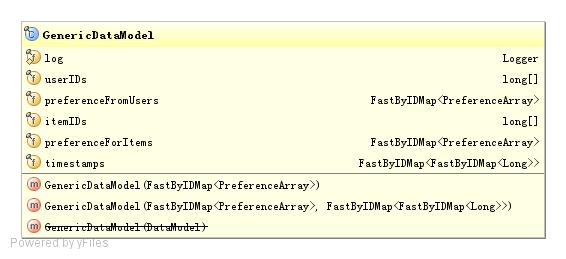
FileDataModel支持文件的读取,Mahout对文件的格式没有太多严格的要求,只要满足一下格式就OK:
· 每一行包含一个用户Id,物品Id,用户喜好
· 逗号隔开或者Tab隔开
· *.zip 和 *.gz 文件会自动解压缩(Mahout 建议在数据量过大时采用压缩的数据存储)
FileDataModel从文件中读取数据,然后将数据以GenericDataModel的形式载入内存,具体可以查看FileDataModel中的buildModel方法。
JDBCDataModel支持对数据库的读取操作,Mahout提供了对MySQL的默认支持MySQLJDBCDataModel,它对用户喜好数据的存储有以下要求:
· 用户ID列需要是BIGINT而且非空
· 物品ID列需要是BIGINT而且非空
· 用户喜好值列需要是FLOAT
· 建议在用户ID和物品ID上建索引
有的时候,我们会忽略用户的喜好值,仅仅只关心用户和物品之间存不存在关联关系,这种关联关系在Mahout里面叫做 “boolean preference”。 之所以会有这类喜好,是因为用户和物品的关联要么存在,要么不存在,记住只是表示关联关系存不存在,不代表喜欢和不喜欢。实际上一条“boolean preference”可有三个状态:喜欢、不喜欢、没有任何关系。
在喜好数据中有大量的噪音数据的情况下,这种特殊的喜好评定方式是有意义的。 同时Mahout为“boolean preference”提供了一个内存版的DataModel——GenericBooleanPrefDataModel

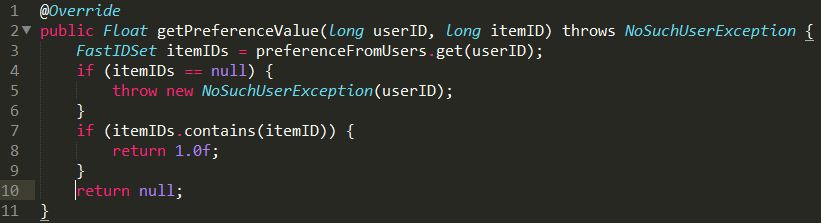
可以看到,GenericBooleanPrefDataModel没有对喜好值进行存储,仅仅只存储了关联的 userId和itemId,注意和GenericDataModel的差别,GenericBooleanPrefDataModel采用了 FastIDSet,只有关联的Id,没有喜好值。因此它的一些方法(继承自DataModel的)如getItemIDsForUser()有更好的执 行速度,而getPreferencesFromUser()的执行速度会更差,因为GenericBooleanPrefDataModel本来就没存 储喜好值,它默认用户对物品的喜好值都是1.0
http://blog.csdn.net/zhoubl668/article/details/13508417